Most documentation on rotating proxies stops at “the IP changes automatically.” That’s true but useless for anyone building production infrastructure. The decisions that determine whether a rotating proxy setup actually works — rotation strategy, session handling, failure modes, connection pooling, header consistency — are never in the marketing copy.
This is the technical layer underneath.
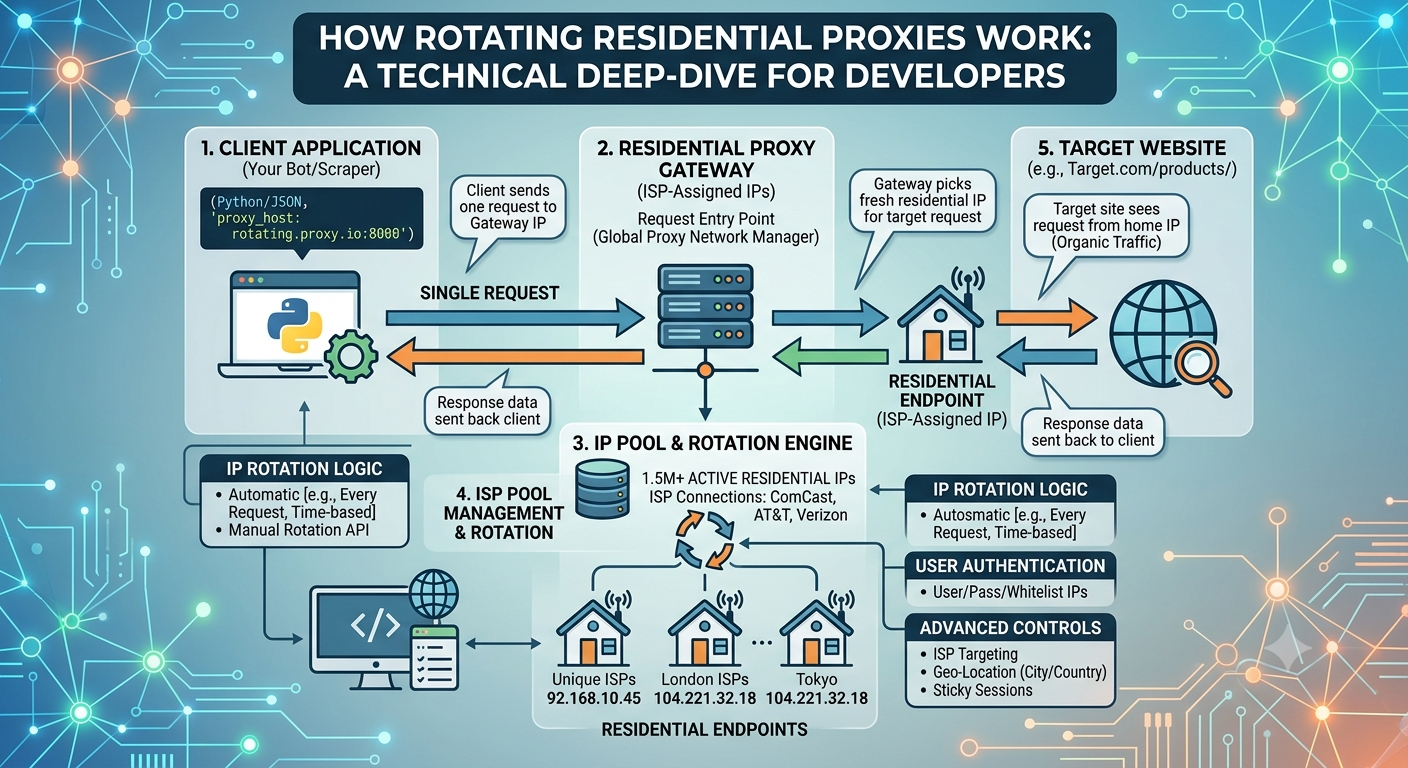
The Architecture of a Rotating Residential Proxy Network
A residential proxy network has three components: the nodes, the gateway, and the routing layer.
Nodes are real consumer devices — laptops, phones, home routers — whose owners have opted into sharing bandwidth through a partner application. Each node has an IP address assigned by a consumer ISP. The node runs a lightweight agent that accepts forwarded traffic, sends it to the target, and returns the response.
The gateway is the single endpoint your code talks to. It accepts your outbound request, applies the routing parameters you specified (country, city, ASN, session type), selects an appropriate node, and forwards the request through it. From your application’s perspective, the gateway looks like a standard HTTP/HTTPS proxy — you point your HTTP client at it and it handles everything downstream.
The routing layer sits between them. It maintains a registry of available nodes, tracks their health and current load, manages session affinity for sticky connections, and handles failover when a node goes offline mid-request.
The rotation happens inside the routing layer. Your code doesn’t implement rotation — it just makes requests, and the network handles which IP each one exits through.
Rotation Strategies
“Rotating proxy” covers several distinct behaviors. Understanding which one you’re using (and which one you need) matters for both scraping effectiveness and data consistency.
Per-request rotation
A new IP is assigned for every request. This is the default mode for most providers and the right choice for stateless scraping — product listings, search results, public profile pages — where each request is independent.
import requests
proxies = {
"http": "http://user:pass@gateway.residentialproxy.io:8080",
"https": "http://user:pass@gateway.residentialproxy.io:8080",
}
# Each of these exits through a different IP
r1 = requests.get("https://target.com/product/1", proxies=proxies)
r2 = requests.get("https://target.com/product/2", proxies=proxies)
r3 = requests.get("https://target.com/product/3", proxies=proxies)
Per-request rotation maximizes IP diversity and makes pattern detection hardest. The tradeoff is that any target behavior tied to session state — personalized pricing, geolocation cookies, A/B test assignment — resets with each request, which can make results inconsistent across a dataset.
Time-based sticky sessions
The same IP is held for a configurable duration, then released and replaced. Common windows are 1, 10, or 30 minutes. Most providers expose this through a session parameter in the proxy URL or authentication string.
# Hold the same IP for up to 10 minutes
proxy_rotating = "http://user:pass@gateway.residentialproxy.io:8080"
proxy_sticky = "http://user-session-abc123:pass@gateway.residentialproxy.io:8080"
# All requests through proxy_sticky use the same IP
# until the session expires or the node goes offline
The session identifier (session-abc123) tells the routing layer to maintain affinity to a specific node. The value can be any string — many implementations use a UUID generated at session start.
Request-count rotation
Less common but useful for specific patterns: the IP rotates after N requests rather than after a time window. This gives more predictable rotation behavior when request cadence is variable.
What Actually Happens on Each Request
Walking through a single request end-to-end:
- Your HTTP client opens a connection to the gateway endpoint and sends a
CONNECTrequest (for HTTPS) or a standard proxied GET (for HTTP). - The gateway authenticates your credentials and parses the routing parameters — either from the username field (common:
user-country-us-city-chicago-session-xyz) or from custom headers. - The routing layer selects a node matching your parameters. For per-request rotation, it picks from the available pool with load balancing and target-domain distribution to avoid sending multiple requests from the same IP to the same domain in a short window.
- The gateway opens a connection to the selected node. The node’s agent receives the forwarded request, strips the proxy-specific headers, and sends it to the target as a normal outbound request from that device.
- The target receives the request from the node’s residential IP. It sees a consumer ISP connection from the specified location. It processes and responds normally.
- The response travels back through the node → gateway → your client. The gateway may add metadata headers (actual exit IP, country, response time) depending on the provider.
For HTTPS, the TLS handshake happens between your client and the gateway, and separately between the gateway and the target. The gateway terminates and re-originates TLS — this is why you need to trust the gateway’s CA certificate, or disable TLS verification in non-production contexts (never in production).
Session Management in Practice
The hardest part of working with rotating proxies isn’t the rotation — it’s maintaining session coherence where you need it while rotating where you don’t.
When sessions matter
Any workflow with multiple dependent requests needs session affinity:
- Login flows: POST credentials → receive session cookie → use cookie on subsequent requests. If the IP changes between the POST and the follow-up GET, the target sees a session cookie arriving from a different location and invalidates it.
- Multi-step forms: Filling a form across multiple pages where the server tracks state by IP + session token.
- Paginated scraping with anti-bot middleware: Some targets assign a “trust score” to an IP over the course of a session. Rotating mid-session resets the score and triggers re-verification.
When rotation is safe
- Each request is fully independent and stateless
- You’re using bearer tokens or API keys rather than session cookies
- The target doesn’t fingerprint across requests within a session
Implementing session/rotation switching
A clean pattern is to parameterize session behavior at the request level:
import uuid
class ProxyClient:
def __init__(self, host, port, user, password):
self.base = f"http://{user}{{session}}:{password}@{host}:{port}"
def rotating(self):
return {"http": self.base.format(session=""),
"https": self.base.format(session="")}
def sticky(self, session_id=None):
sid = session_id or uuid.uuid4().hex[:8]
tag = f"-session-{sid}"
return {"http": self.base.format(session=tag),
"https": self.base.format(session=tag)}, sid
client = ProxyClient("gateway.residentialproxy.io", 8080, "user", "pass")
# Stateless scraping — rotate every request
for url in product_urls:
r = requests.get(url, proxies=client.rotating())
# Login flow — hold the same IP
proxies, sid = client.sticky()
session = requests.Session()
session.proxies = proxies
session.post("https://target.com/login", data=creds)
session.get("https://target.com/account/orders")
Failure Modes and Handling
Nodes go offline. Consumer devices lose connectivity, sleep, or get reassigned. A production scraper needs to handle this explicitly.
Node dropout mid-session. If a sticky session node goes offline, the gateway should automatically reassign to a new node. The new node will have a different IP, which may invalidate session cookies on the target. Detect this with a response inspection check (redirect to login page, 401, unexpected content) and re-authenticate.
IP soft-blocks. Some targets don’t hard-block IPs — they slow-roll them: increased CAPTCHA rates, delayed responses, subtly wrong data. These are harder to detect than 403s. Implement content validation on responses, not just HTTP status checks.
def is_valid_response(r, expected_selector):
if r.status_code != 200:
return False
if "captcha" in r.text.lower():
return False
if expected_selector not in r.text:
return False
return True
Gateway timeouts. A residential node is a consumer device with variable connectivity. P99 latency on a rotating residential pool is meaningfully higher than the average — plan for it with appropriate timeouts and retry logic.
try:
r = requests.get(url, proxies=proxies, timeout=(5, 30))
except requests.exceptions.ProxyError:
# Node unreachable — retry with new rotation
pass
except requests.exceptions.ReadTimeout:
# Node connected but response too slow — log and skip
pass
Retry strategy. Blind retries on failure exhaust your traffic budget on bad nodes. A better pattern: retry with a new rotation on ProxyError, retry with same proxy on transient network errors (ConnectionReset on established connections), and skip + log on consistent content validation failures that suggest a soft-block on that target.
Header Management
The biggest technical mistake in rotating proxy setups is inconsistent headers across requests. If your scraper sends different User-Agent values on different requests, or omits standard browser headers, the inconsistency is a detection signal regardless of IP rotation.
Maintain a consistent browser profile across all requests in a session:
HEADERS = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) "
"AppleWebKit/537.36 (KHTML, like Gecko) "
"Chrome/124.0.0.0 Safari/537.36",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
"Accept-Language": "en-US,en;q=0.5",
"Accept-Encoding": "gzip, deflate, br",
"Connection": "keep-alive",
"Upgrade-Insecure-Requests": "1",
"Sec-Fetch-Dest": "document",
"Sec-Fetch-Mode": "navigate",
"Sec-Fetch-Site": "none",
}
For rotation setups, the User-Agent should match the OS/browser profile appropriate to the target geography — a Japanese residential IP paired with a US English browser profile is a detectable inconsistency on sophisticated targets.
Concurrency and Rate Limiting
A common mistake is treating rotating proxies as permission to send unlimited concurrent requests. They’re not.
Each node has limited bandwidth. The routing layer distributes load across the pool, but if you’re sending 100 concurrent requests to the same domain, you’re likely hitting it from 100 different IPs in a short window — which is itself a detectable signal (volume anomaly from a residential ASN range).
Effective concurrency management:
- Per-domain rate limits are more important than global rate limits. 10 concurrent requests across 10 different domains is less risky than 10 concurrent requests to one domain.
- Jitter between requests to the same domain. Deterministic intervals (exactly 1.0 seconds) are easier to detect than randomized ones (0.8–1.4 seconds).
- Respect crawl delays in robots.txt not because you’re legally required to, but because ignoring them is a signal.
Choosing the Right Pool for the Target
Not all residential IP pools are the same, and the right pool depends on the target.
Pool size matters for high-volume scraping. A pool of 1M IPs sounds large until you’re sending 500K requests per day to the same domain — the expected reuse rate approaches 50%, and reused IPs on the same target accumulate soft-blocks faster.
ASN diversity matters for sophisticated targets. Some detection systems flag traffic when too many requests come from residential IPs in the same ISP — if a pool is heavily weighted toward one carrier, this becomes visible.
Geographic accuracy matters for geo-dependent data. A residential IP that claims to be in Tokyo but geolocates to a different city in third-party IP databases (which the target may also query) creates inconsistency. Providers with accurate, well-maintained geolocation data avoid this.
ResidentialProxy.io exposes city and ASN-level targeting through the standard username parameter format, with a pool of 100M+ IPs across 210+ countries — sufficient depth for high-volume rotation without significant IP reuse on any single domain.
What Rotation Doesn’t Solve
Rotating residential IPs removes the most obvious detection signal. It doesn’t remove all of them.
TLS fingerprinting. The TLS handshake from a Python requests client has a different cipher suite order, extension list, and record structure than Chrome. Libraries like curl-impersonate or browser automation tools (Playwright, Puppeteer) can match a real browser’s TLS fingerprint if the target inspects it.
HTTP/2 fingerprinting. Similar to TLS — the HTTP/2 SETTINGS frame from a Python client differs from a browser’s. Targets using HTTP/2 fingerprinting (Cloudflare’s Bot Management does this) will flag requests regardless of IP.
Behavioral patterns. A scraper that hits a page, immediately extracts exactly one element, and exits in 50ms every time has a different behavioral profile than a human who takes 2–8 seconds to read a page and triggers several additional resource requests (images, scripts, analytics). For hardened targets, behavioral mimicry matters as much as IP legitimacy.
Rotating residential proxies are the correct foundation. They’re necessary but not always sufficient for the hardest targets.
Summary
The rotation mechanism itself is simple — a gateway selects a different node per request. The complexity is in everything around it: session strategy, failure handling, header consistency, concurrency management, and understanding where IP rotation ends and other detection vectors begin.
Build for those failure modes explicitly, and rotating residential proxies become reliable infrastructure rather than a fragile scraping workaround.